
经典的五层模型
我们先来看一张概念图:
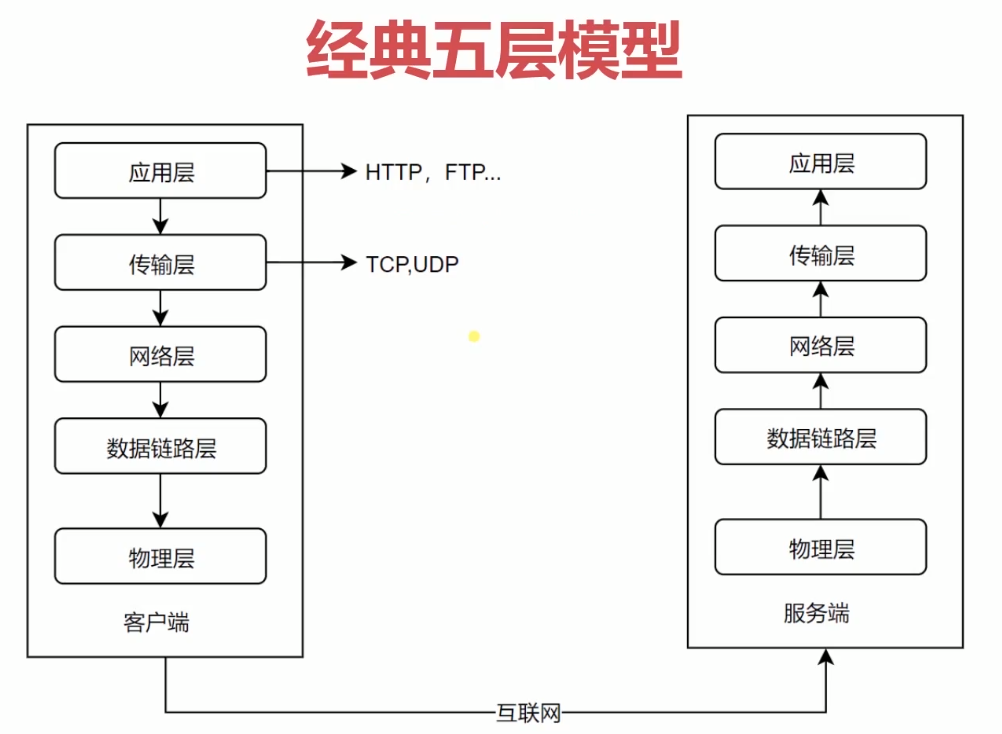
在网络协议当中,我们一般在谈论到整个网络信息传输的一个过程的时候都会套用这个经典的五层模型。可以看到,在我们经典的五层模型中,分别有应用层、传输层、网络层、数据链路层、物理层。任何计算机在网络传输上都具备上面这五层模型,所以无论是远程服务器,还是自己的电脑都具备这五层模型。这一就是为什么我们自己的计算机也能作为服务器来提供网络服务的原因。
1、物理层
物理层很好理解,根据字面意思就能猜到物理层是什么。物理层的主要作用是定义物理设备如何传输数据。简单来说物理层就是我们的电脑硬件,我们的网卡端口,网线,网线连出去之后的光缆,光缆可能要经过上千公里去连接对方的服务器。
- 数据链路层
数据链路层是在通信实体间建立数据链路的连接。可以理解为,电脑中0101的东西。
- 网络层
网络层为数据在结点之间传输创建逻辑链路。比如我们要连接百度的服务器,那我们该如何寻找百度这台服务器的地址就是一个逻辑关系,这个逻辑关系就是在网络层创建的。
- 传输层
向用户可靠的端到端(End-to-End)服务。在web开发中,传输层主要还是依赖于TCP,UPD两个协议。传输层到底是干什么的呢? 设想,当我们输入一个域名后,发送Http请求,
由于我们发送请求的大小并不确定,可大可小,对于大的内容我们不能直接把数据传输过去,传输层会对这些数据进行分包或者分片处理,以保证我们的数据可以可靠地发送给服务器。同样,当服务器向客户端返回数据的时候也会经过传输层的分片和分包处理,以保证可以可靠地将数据换回给客户端。
- 应用层
对于web开发者来说,应用层是接触最多的层面,我们的Http请求就是实现在应用层,http协议是构建在TCP协议之上的。为我们提供了很多方便的服务,比如ajax。
http发展历史及个版本区别
HTTP/0.9
-
只有一个命令GET
-
没有HEADER等描述数据的信息
-
服务器发送完毕,就关闭TCP连接
HTTP/1.0
-
增加了很多命令
-
增加了status code和header
-
多字符集支持、多部分发送、权限、缓存
-
服务器发送完毕,就关闭TCP连接
HTTP/1.1
- 持久连接:
在HTTP1/0.9和1.0中,当服务器发送完毕就直接关闭TCP连接,这样但我们请求多次且都走相同连接时就会存在性能浪费的问题,成本较高。而在1.1中,这个缺点得到了改善,在进行TCP连接之后,并不急着关闭连接,如果在同一个连接中发送多次请求则可以在已经创建好的TCP连接上直接传输数据。
- 增加pipeline:
虽然我们可以在同一个连接中发送多个请求。但是对于服务端,我们是要按照接收到请求的顺序将数据进行返回。但是这就造成了一个问题,如果前一个请求的处理时间非常长,而后一个请求的处理时间比较快,那么前一个请求就会阻塞下一个请求的处理,下一个请求不会因为他可以被快速处理而被先发送,必须等待前一个请求发送完成才可发送。这是一个串行同步的过程。
- 增加了host和其他的一些命令:
host的存在实现了同一个物理服务器可以部署多个网络服务(分布式,集群)。这就好比这样一个场景:在同一个物理服务器上,里面跑了nodejs的服务,也跑了java的服务,对于一个请求,判断我们要访问的是这个物理服务器里的哪个服务这就需要host来做出区分。
http/2.0
- 所有数据都以二进制传输:
这个改善直接解决了1.1中文件串行返回造成性能浪费的问题。因为在1.1之前的传输中,大部分的数据传输都是以字符串的方式传输的,所以对数据的分片方式是不太一样的。但是在2.0中所有的数据都是以‘帧’来进行传输的,所以在服务器就无需按照请求的顺序进行返回处理了。这样就实现了并行返回数据的异步过程。也就是(2)中描述这个特点。
-
同一个连接里面发送多个请求不再需要按顺序处理
-
头信息压缩:
在1.1及之前的版本中,HEADER中的一些信息,诸如content-type, cache-control等都是通过字符串的方式储存的,这无疑会增加HEADER的大小,增大带宽消耗,而2.0对HEADER中的数据进行了压缩,减少了HEADER的大小,也就减小了带宽的消耗。
- 具备服务端推送功能:
举一个例子:当我们在像某个服务器请求html文件时,在1.1及之前的版本中,服务端只会返回html文件,只有等客户端在解析html文件时才会进而发送一些其他的请求,比如css、js、img等,然后服务端在继续返回这些文件。
在2.0中,推送功能使得服务端的响应更聪明,他可以在返回数据之前猜测一下这个文件在交给客户端后,客户端是否可能因解析这个文件中的内容而再次请求一些其他相关文件。比如上例中,html的请求发送后,服务端就会聪明的分析一下这个html所依赖的文件还有什么,然后把这些文件数据和这个html文件一起返回。这样客户端在需要依赖文件的时候,就不需要再次请求服务端去获取相关的文件数据。




