
一、浏览器储存各种方式
因为试验品不好找,之后补上。实在不行截图视频,详情见性能优化7-4
cookie实现用户信息存储
很多网站都是通过服务端种cookie的形式将cookie种到用户的浏览器中。这样在之后的每一次的http请求中,都可以将cookie中的信息携带在请求头中,以便于服务端可以直接通过请求头得到用户信息。
但是这种方式并不适用于任何场景,虽然他更加的方便于前后端交互,但是不分文件的请求都携带上cookie是一种浪费!比如一些静态文件:js、css、图片….他们根本不需要请求头中携带的用户信息。
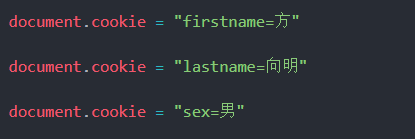
cookie存储用户信息的方式
这是一种非常常见的浏览器存储方式,不多赘述:

TIPS:
-
就像刚刚说的那样,他只是和存储用户信息这样小的东西(<=5k),当我们企图利用cookie中的信息传递请求头时,那些不区分用户的文件请求不应该携带cookie信息。
-
cookie并不是浏览器推荐的做法,有很多cookie都设置了httponly,这也就是说我们不能通过js去获取或者修改他们。另外,cookie的本意就并非支持可以让js操作cookie,因此cookie的API缺乏。
localStorage实现静态资源缓存
localStorage是个好东西,存储空间更大,足足有4M,储存方式也很常用,在这里不多赘述。各种API更适合我们操作。详细信息可以见MDN:
https://developer.mozilla.org/zh-CN/docs/Web/API/Window/localStorage
举个例子:


对于localStorage最秀的操作我认为还是他对一些脚本的储存。将需要的静态资源存入localStorage中,就相当于缓存了这些静态资源,下次需要这些资源的时候可以通过判断localStorage中是否已经存在相关资源的缓存来判断是否需要重新发起请求,如果缓存中有,那就根本不需要重新开一个http请求去从服务器获取文件,直接从缓存中读取,明显能大幅度提升流量、性能和缓存的优势。最常见的通过locaStoragel缓存的就是js文件和css文件了。
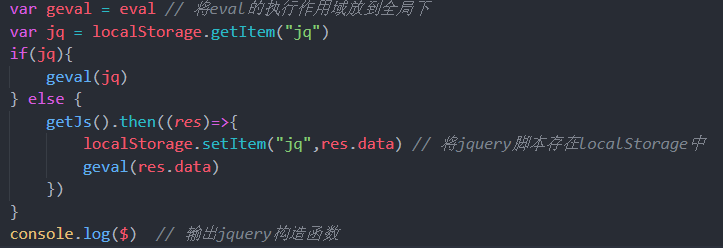
接下来利用localStorage缓存文件的简单的例子,我们希望请求一个静态的js文件,然后假设这个js文件很大。首次请求我们正常去发送http请求,然后把接受的js文件存到localStorage中,然后重新刷新浏览器,查看下次是否有再次请求:
- 创建发起请求处理主要逻辑的js文件,在这里用自己在项目中封装的getJs,本质上是一个axios:

直接请求jquery的CDN。
- 将首次请求到的js文件存储到localStorage中,同时放在eval中执行


- 在每次进入网页的时候先检查localStorage中是否存在相应脚本
-
如果存在相应脚本的缓存,就直接放在eval中执行即可
-
最终的完整的代码;
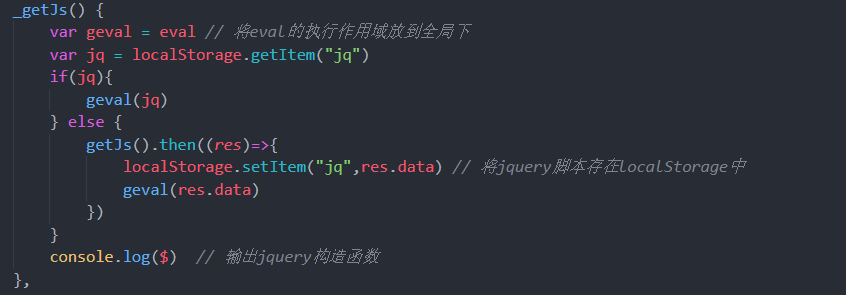
当我们清空localStorage,重新刷新页面,可见什么都没有:

之后刷新页面,因为没有jq,所以会重新进行请求jq文件,并重存jq:

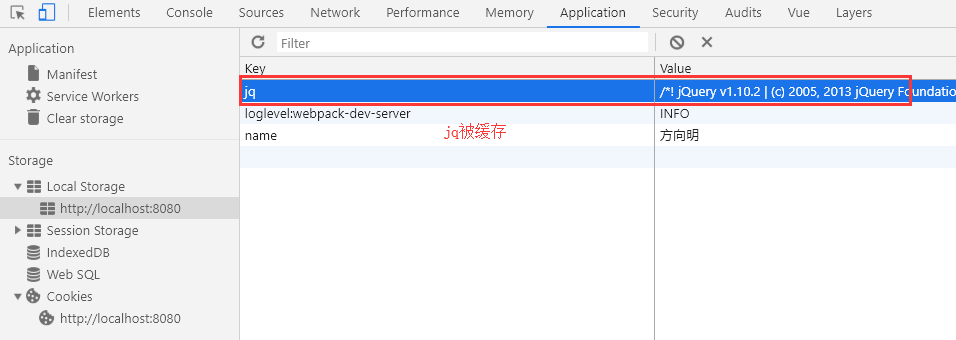
查看打印结果:

之后再次重新刷新:
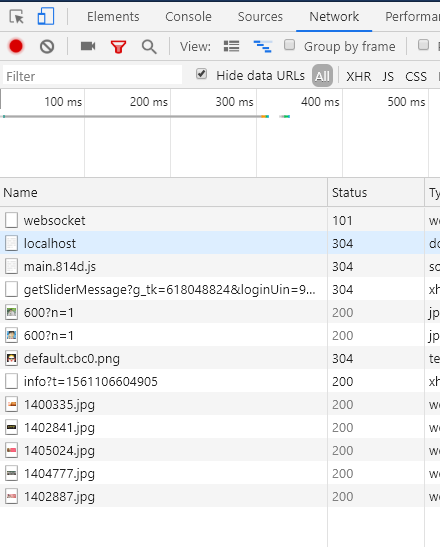
我们发现所有请求中都没有jquery!localStorage中也存入了jq
回到控制台再次查看打印:
发现打印成功,这就意味着从缓存中读取上一次存入的jq成功!第二次访问页面的http请求流量就这么被节省下来。
TIPS:之前发现百度疯狂利用localStorage去缓存静态文件,似乎整个百度地图的js和css文件都被存入了localStorage中。
indexeDB实现数据存储
1、indexdb的创建
indexedDB也是浏览器端存储数据的一种方案,他的存储的数据相比localStorage可以更大更复杂。IndexedDB 为生成 Web Application 提供了丰富的查询能力,使我们的应用在在线和离线时都可以正常工作。并且也有很多原生接口供我们使用。
先来打印看看indexedDB:


可以看到,window.indexedDB返回一个IDNFactory对象,其中包含了open和deleteDatebase方法。接下来我们就通过open来创建一个indexedDB。看看他会返回什么。


我们可以看到,open(‘testDB’)会返回一个叫做testDB的IDBOpenDBRequest的对象,其中包含了这个indexedDB的生命周期的回调函数,还有他的readyState状态、响应回来的indexedDB主体result……说白了这个request并是不是db的本体,可以理解为他只是一个申请indexedDB的请求。就像在ajax中常用的xhr变量一样,他并不是响应主体,只是包含了响应主体的一个包含更多信息的对象。
接下来我们来看一下indexedDB的操作和管理:
- 首先我们需要写好一个用于存放db对象各种配置信息的对象
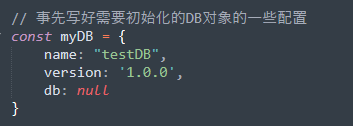
其中db是我们用来存放open后返回的db实例的结果也就是db.result。
(2)然后我们封装一个openDB用来创建db对象并设置回调:
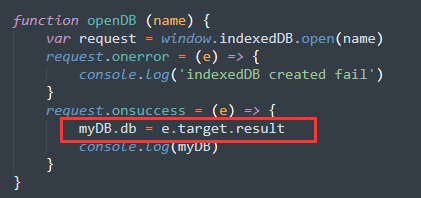
红色框起来的部分是需要特别注意的,通过e.target就相当于是request。
我们大可以这样做一个判断来验证他:
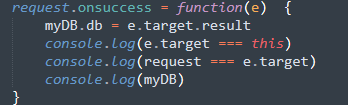

这样我们也就见证了e.target的,也就知道了myDB.db中到底存储的是什么东西,他就是request.result。
在创建完成indexedDB后我们就可以在application工具中发现他:

indexedDB的关闭和删除
为了体验关闭和删除,我们略改变openDB方法,为他添加一个可以设置的回调函数。
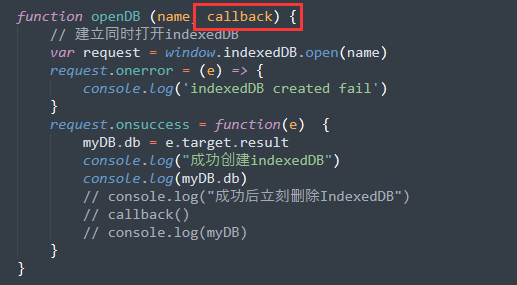
- 关闭indexedDB主要使用indexedDB对象为我们提供的close接口。
为了能够看得清晰,我们在onsuccess中先打印创建好的indexDB。

之后我们设置回调函数,还是在onsuccess中进行关闭,我们企图在onsuccess的时候就把刚刚创建好的indexedDB关闭。

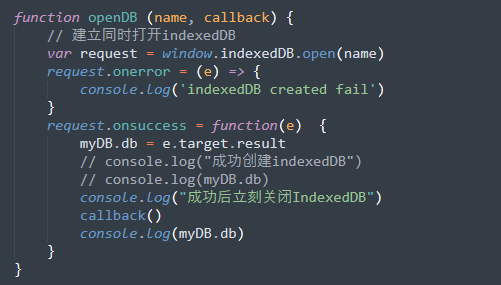
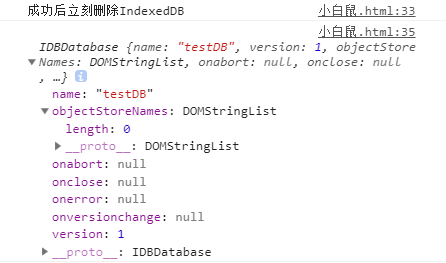
看上去好像并没有什么变化,但是此时我们已经无法对indexDB储存的信息进行增删查改操作。
TIP: 关闭之后,我们仍可以在aplication中找到testDB.
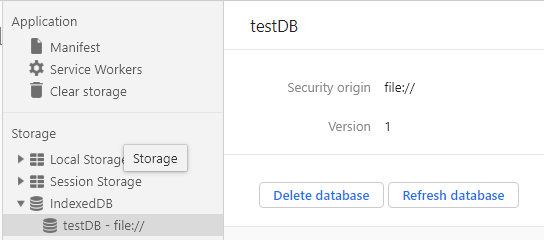
我们操作删除和关闭的操作方法类似。但是需要注意的是,删除的接口是部署在window.indexedDB上的,而不是db实例上的。
我们对openDB方法不做修改,还是在创建成功的时候立刻删除,来看一看效果。

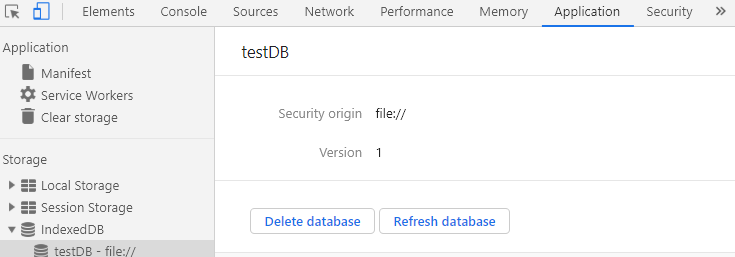
还是一样的对象,一样可以在application中访问得到。
这里我们遗留了一个问题,我们发现无论是关闭还是删除,我们都能够在application中访问到数据库,而且打印出的db实例也总是一样的。我怀疑删除和关闭和创建indexedDB一样是一个异步的过程。
indexedDB的基本操作——初始化
IndexedDB普通的数据不同,他没有一个表的概念,相对的,用来充当表的是一个ObjectStore。要想让indexedDB存放数据,我们首先得创建一个ObjectStore,这个ObjectStore顾名思义,他就是一个对象的仓库,每个对象就是一个元组,因此他们也必然有相同键值。所以我们得从创建ObjectStore(建表)开始。
建表有着极大关键要素:
-
表要有一个名称
-
表要有字段和一个主键
-
每一个字段下的值还有一些规定,比如:是否唯一…
开始建表:
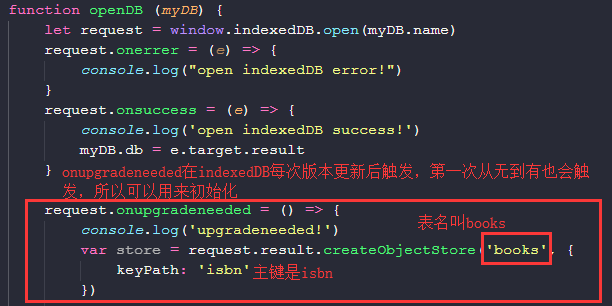
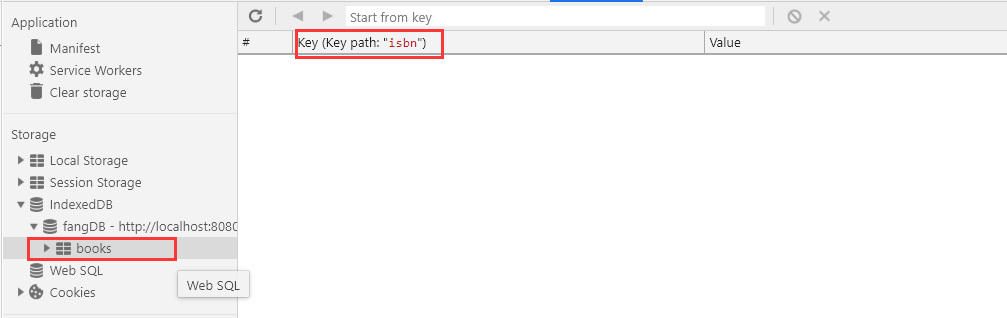
我们可以看到books就是我们fangDB下的一个表了。并且主键为isbn。
之后我们初始化字段,然后为这些字段中插入一些初始值:
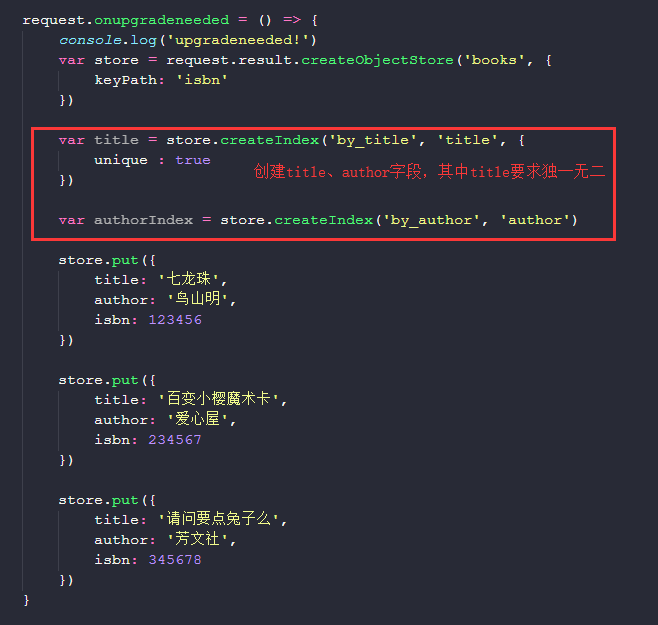
TIP: 需要注意的是,createIndex是创建表中字段,所以是对表而言的,因此是store.createIndex,而不是request.result。
下面的store.put就是往表中插值的过程。我们来看一下插值之后的变化:
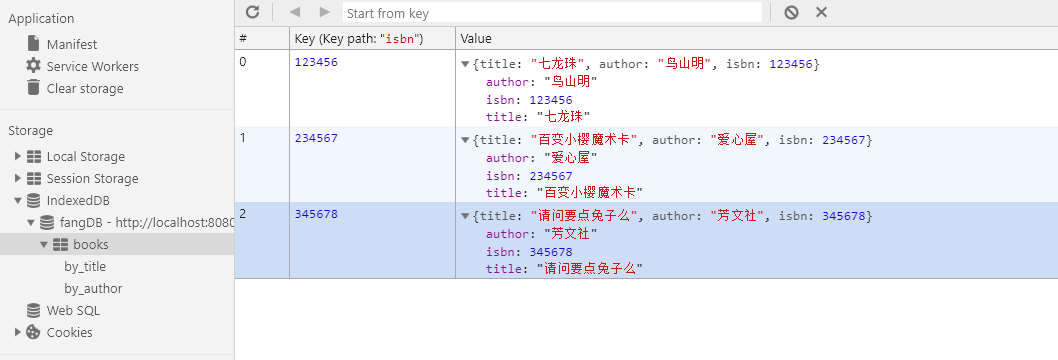
可以很清晰地看到,表中每个主键后对应的值都是我们一个具有相同字段的对象。
我们在createIndex中设置的by_title和by_author都相当于是为根据字段的值显示数据的方式提供了一个接口。


TIPS: 因为我们的表的初始化插值是在upgradeneeded事件触发后进行的,在我们修改初始化插值的逻辑后,如果之前有了已经创建好的IndexedDB,下次更新的时候就不会经历upgradeneeded的过程,因此为了有效更新初始化操作,我们需要在每次刷新前删除已经存在的indexedDB。
indexedDB基本操作——增删改查
要想实现indexedDB的增删改查不得不提到‘事务’这个概念,事务是对ObjectStore的一系列操作关联,这个关联相当于配置好接下来的增删改查是对那个ObjectStore而言的,并且操作的读写权限又是什么。我们需要初始化事务transaction。
1、增添数据 store.add()

- 删除数据 store.delete()

- 查找数据 和 修改数据





