webpack浏览器缓存
用户第一次访问页面的时候,会加载页面所要的资源,并存在缓存里,下次用户再次访问同样的页面的时候就会从缓存中读取数据。浏览器读取页面缓存的方式是通过比较两次文件的名称是否一样,这也就造成了,如果修改代码,不修改文件名,就很可能让用户在下次访问网页的时候错认为没有发生变更。
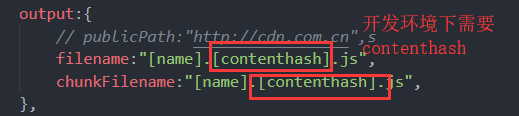
为了解决这个问题,我们可以借助webpack提供给我们的content hash,核心原理就是给outputfile的命名加一个contenthash,这个contenthash在当我们的代码发生变化的时候就会发生变化,这样在当文件内容改变的时候,用户的浏览器也会分辨出文件名的变化。从而避免读取缓存。
开发环境下无所谓,可以不必使用contenthash,因为hmr已经帮助我们解决缓存的问题,而且通常我们也会强制刷新页面,毕竟这是在开发环境下嘛。
但是如果是在生产环境下,我们就需要配置好contenthash。


然后build(生产环境)打包两次。
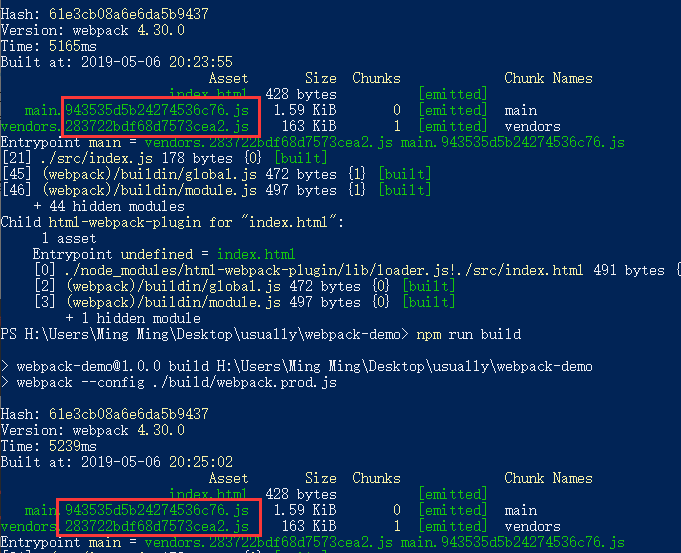
我们可以看到,直接打包两次,中间不修改任何代码,两次打包生成的contenthash是完全相同的。
如果修改index.js的代码,contenthash就会发生变化。没有改变的文件依旧不会发生改变。
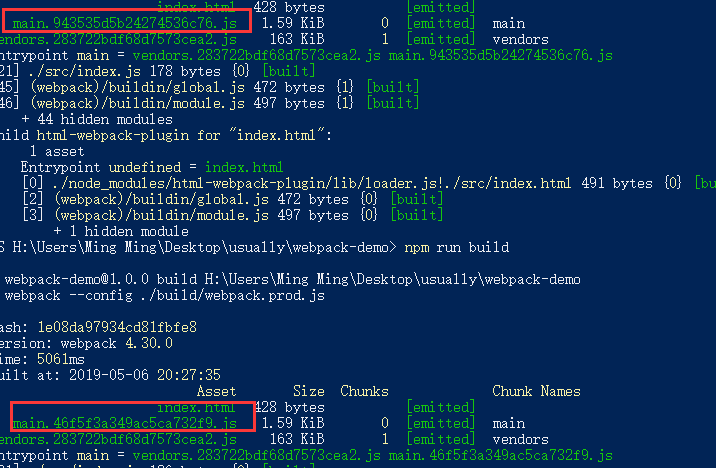
TIPS:在webpack4的早期版本中,配置contenthash后,我们可能会发现每次打包尽管不修改代码都会改变contenthash,这是因为我们的库(静态资源vendors)和我们的业务代码(main.js)之间是有一定的关联的。这一部分关联的代码叫做manifest。manifest存在于main.js也存在于vendors.js里面。Webpack4的早期版本中,每次打包manifest都会存在差异,所以导致每次打包即使没有更改我们写的代码,contenthash的还是变更了。
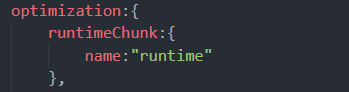
通过配置如下选项,我们就可以将manifest的代码从main和vendors中分离出来,从而保证了每次打包,main和vendors的代码不会改变,他们两个的contenthash也就不会发生改变了。